时间:2023-08-27 02:11 / 来源:未知
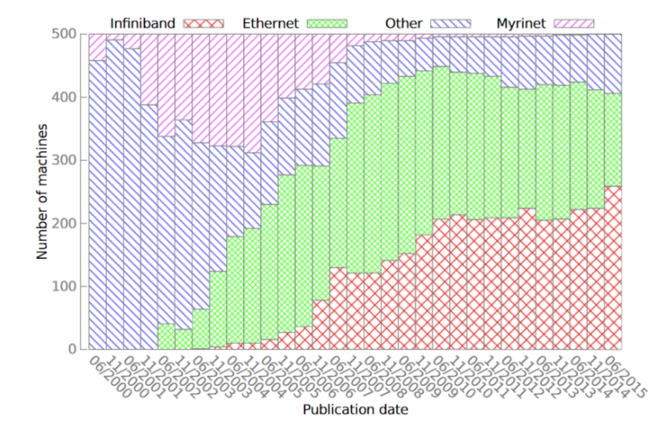
drcfx外汇骗局天河自研系列网络正在从前的高职能策动(HPC)体例中,往往会采用极少定制的汇集办理计划,比方:Myrinet、Quadrics、InfiniBand,而不是以太网。这些汇集可能挣脱以太网计划正在打算上的范围,可能供应更高的带宽、更低的延迟、更好的堵塞把握、以及极少特有的功效。
IBTA正在2010年揭橥了RoCE(RDMA over Converged Ethernet)订交本事圭臬,随后又正在2014年揭橥了RoCEv2订交本事圭臬,同时带宽上也有大幅晋升。以太网职能的大幅晋升,使越来越众的人思要采用能兼容古板以太网的高职能汇集办理计划。这也冲破了top500上运用以太网的HPC集群数目越来越少的趋向,使以太网现正在已经占据top500的半壁山河。
固然现正在Myrinet、Quadrics依然没落,但InfiniBand已经攻克着高职能汇集中主要的一席之地,其它Cray自研系列汇集,河汉自研系列汇集,Tofu D系列汇集也有着其主要的身分。
RoCE订交是一种能正在以太网进步行RDMA(长途内存直接访候)的集群汇集通讯订交。它将收/发包的就业卸载(offload)到了网卡上,不须要像TCP/IP订交相同使体例进入内核态,削减了拷贝、封包解包等等的开销。如许大大下降了以太网通讯的延迟,削减了通信时对CPU资源的占用,缓解了汇集中的堵塞,让带宽获得更有用的使用。
RoCE订交有两个版本:RoCE v1和RoCE v2。个中RoCE v1是链途层订交,以是运用RoCEv1订交通讯的两边必需正在统一个二层汇集内;而RoCE v2是汇集层订交,于是RoCE v2订交的包可能被三层途由,具有更好的可扩展性。
RoCE订交保存了IB与运用标准的接口、传输层和汇集层,将IB网的链途层和物理层替代为以太网的链途层和汇集层。正在RoCE数据包链途层数据帧中,Ethertype字段值被IEEE界说为了0x8915,来证明这是一个RoCE数据包。可是因为RoCE订交没有承受以太网的汇集层,正在RoCE数据包中并没有IP字段,于是RoCE数据包不行被三层途由,数据包的传输只可被范围正在一个二层汇集中途由。
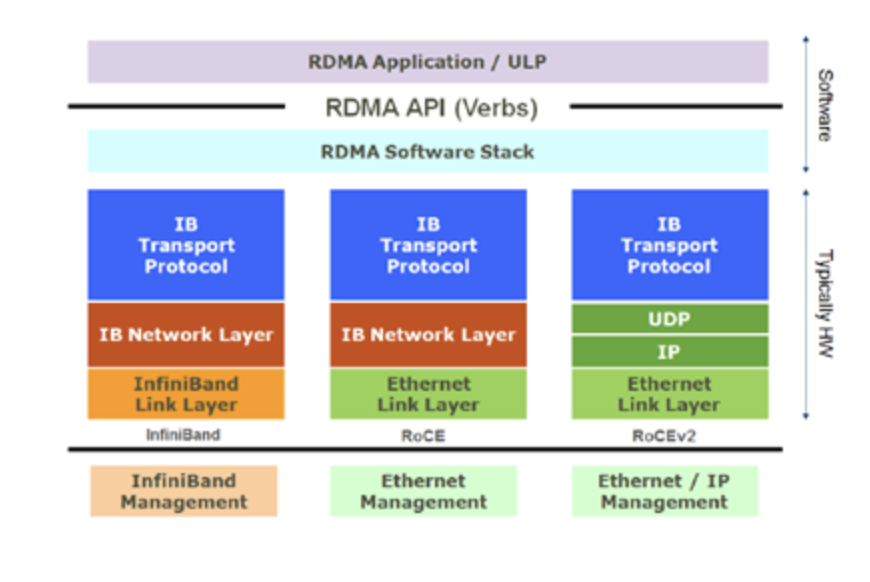
RoCE v2订交对RoCE订交举办了极少改良。RoCEv2订交将RoCE订交保存的IB汇集层局部替代为了以太网汇集层和运用UDP订交的传输层,而且使用以太网汇集层IP数据报中的DSCP和ECN字段竣工了堵塞把握的功效。于是RoCE v2订交的包可能被途由,具有更好的可扩展性。因为RoCE v2订交现正在依然整个庖代存正在缺陷的RoCE订交,人们正在提到RoCE订交时平常也指的是RoCE v2订交,故本文中接下来提到的一起RoCE订交,除非稀奇声明为第一代RoCE,均指代RoCE v2订交。
正在运用RoCE订交的汇集中,一定要竣工RoCE流量的无损传输。由于正在举办RDMA通讯时,数据包必需无丢包地、按程序地抵达,假若闪现丢包或者包乱序抵达的情形,则一定要举办go-back-N重传,而且愿望收到的数据包后面的数据包不会被缓存。
RoCE订交的堵塞把握共有两个阶段:运用DCQCN(Datacenter Quantized Congestion Notification)举办减速的阶段和运用PFC(Priority Flow Control)暂停传输的阶段(固然端庄来说唯有前者是堵塞把握计谋,后者实在是流量把握计谋,可是我风气把它们作为堵塞把握的两个阶段,后文中也这会这么写)。
当正在汇集中存正在众对一通讯的情形时,这时汇集中往往就会闪现堵塞,其完全阐扬是相易机某一个端口的待发送缓冲区音讯的总巨细急速伸长。假若情形得不到把握,将会导致缓冲区被填满,从而导致丢包。于是,正在第一个阶段,当相易机检测到某个端口的待发送缓冲区音讯的总巨细到达必然的阈值时,就会将RoCE数据包中IP层的ECN字段举办标帜。当吸收方吸收到这个数据包,呈现ECN字段依然被相易机标帜了,就会返回一个CNP(Congestion Notification Packet)包给发送方,指点发送方下降发送速率。
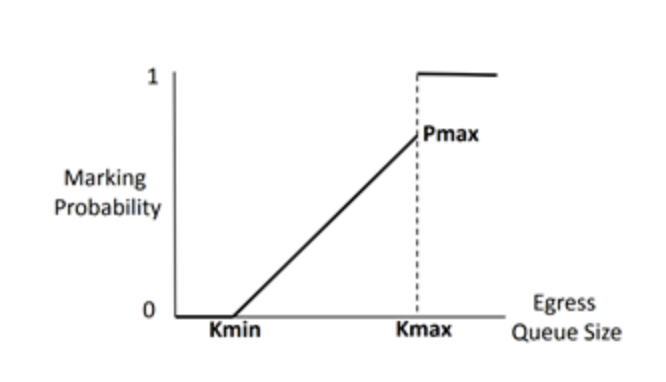
须要稀奇提防的是,对待ECN字段的标帜并不是到达一个阈值就一概标帜,而是存正在两个Kmin和Kmax,如图2所示,当堵塞部队长度小于Kmin时,不举办标帜。当部队长度位于Kmin和Kmax之间时,部队越长,标帜概率越大。当部队长度大于Kmax时,则一概标帜。而吸收方不会每收到一个ECN包就返回一个CNP包,而是正在每一个功夫间隔内,假若收到了带有ECN标帜的数据包,就会返回一个CNP包。如许,发送方就可能凭据收到的CNP包的数目来调治自身的发送速率。
当汇集中的堵塞情形进一步恶化时,相易机检测到某个端口的待发送部队长度到达一个更高的阈值时,相易机将向音讯原因的上一跳发送PFC的暂停把握帧,使上逛供职器或者相易机暂停向其发送数据,直到相易机中的堵塞获得缓解的时间,向上逛发送一个PFC把握帧来告诉上有一直发送。因为PFC的流量把握是助助按区别的流量通道举办暂停的,于是,当修立好了每个流量通道带宽占总带宽的比例,可能一个流量通道上的流量传输暂停,并不影响其他流量通道上的数据传输。
值得一提的是,并不是每一款声称助助RoCE的相易机都完满的竣工了堵塞把握的功效。正在我的测试中,呈现了某品牌的某款相易机的正在爆发堵塞时,对来自区别端口但注入速率沟通的流量举办ECN标帜时概率区别,导致了负载不屈衡的题目。
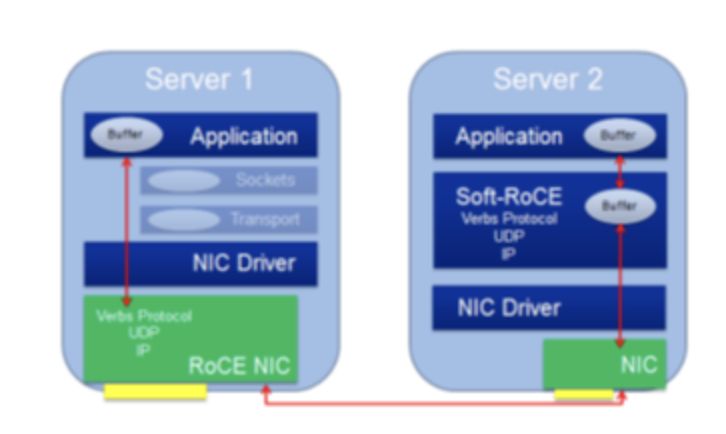
固然现正在大局部的高职能以太网卡都能助助RoCE订交,可是已经有极少网卡不助助RoCE订交。于是IBM、Mellanox等联手创修了开源的Soft-RoCE项目。如许,正在安置了不助助RoCE订交的网卡的节点上,已经可能采用运用Soft-RoCE,使其具备了能与安置了助助RoCE订交的网卡的节点运用RoCE订交举办通讯的才略,如图3所示。固然这并不会给前者带来职能晋升,可是让后者或许填塞外现其职能。正在极少场景下,例如:数据中央,可能只将其高IO存储供职器升级为助助RoCE订交的以太网卡,以普及举座职能和可扩展性。同时这种RoCE和Soft-RoCE勾结的设施也可能知足集群慢慢升级的需求,而不必一次性一概升级。
我以为HPC汇集的焦点需求有两个:①低延迟;②正在急速改变的流量形式下已经能依旧低延迟。
对待①低延迟,RoCE即是用来办理这个题目的。如前面提到的,RoCE通过将汇集操作卸载到网卡上,竣工了低延迟,也削减了CPU的占用。
对待②正在急速改变的流量形式下已经能依旧低延迟,实在即是堵塞把握的题目。可是环节正在于HPC的流量形式是急速改变的,而RoCE正在这个题目上阐扬是欠佳的。

固然IB用的是100G的,RoCE用的是25G的,可是这里咱们闭心的是延迟,该当没相闭系。
可能看出,固然RoCE订交简直能大幅下降通讯延迟,比TCP疾了5倍支配,但已经比IB慢了47%-63%。
上面用到的以太网相易机SN2410的官方延迟数据是300ns,固然IB相易机CS7520没找到官方延迟数据,然而找到了同为EDR相易机的SB7800的官方数据,延迟为90ns。
然而上面这些是有些旧的前两年的兴办了,新一点的Mellanox以太网相易机SN3000系列的200G以太网相易机官方延迟数据是425ns,更新的Mellanox SN4000系列400G以太网相易机,正在官方文档没有找到延迟数据。新一点的Mellanox IB相易机QM8700系列HDR相易机的官方延迟数据是130ns,最新的QM9700系列NDR相易机,正在官方文档中也没有找到延迟数据。(不明了为啥都是新一代的比旧的延迟还大一点,况且最新一代的延迟都没放出来)
定制汇集的Cray XC系列Aries相易机延迟大约是100ns,河汉-2A的相易机延迟也大约是100ns。
可睹正在相易机竣工上,以太网相易机与IB相易机以及极少定制的超算汇集的延迟职能仍然有必然差异的。
假设咱们要运用RoCE发送1 byte的数据,这时为了封装这1 byte的数据包要特地付出的价钱如下:
假设咱们要运用IB发送1 byte的数据,这时为了封装这1 byte的数据包要特地付出的价钱如下:
假若是定制的汇集,数据包的组织可能做到更简陋,例如河汉-1A的Mini-packet (MP)的包头是有8 bytes。
由此可睹,以太网艰巨的底层组织也是将RoCE运用到HPC的一个阻挡之一。
数据中央的以太网相易机往往还要具备很众其他功效,还要付出很众本钱来举办竣工,例如SDN、QoS等等,这一块我也不是很懂。
对待这个以太网的这些features,我挺思明了:以太网针这些功效与RoCE兼容吗,这些功效会对RoCE的职能爆发影响吗?
RoCE订交的两段堵塞把握都存正在必然的题目,也许难以正在急速改变的流量形式下已经能依旧低延迟。
采用PFC(Priority Flow Control)采用的是暂停把握帧来避免吸收到过众的数据包从而惹起丢包。这种设施比起credit-based的设施,buffer的使用率不免要低极少。由其对待极少延迟较低的相易机,buffer会相对较少,此时用PFC(Priority Flow Control)就欠好把握;而假若用credit-base则可能竣工愈加切确的统制。
DCQCN与IB的堵塞把握比拟,实在大同小异,都是backward notification:通过通过先要将堵塞音信发送到目标地,然后再将堵塞音信返回到发送方,再举办限速。可是正在细节上略有区别:RoCE的降速与提速计谋凭据论文Congestion Control for Large-Scale RDMA Deployments,是固定死的一套公式;而IB中的可能自界说提速与降速计谋;固然大局部人该当本质上该当都用的是默认装备,可是有自正在度总好过没有叭。再有一点是,正在这篇论文中测试的是每N=50us最众爆发一个CNP包,不明了假若这个值改小行不可;而IB中思对应的CCTI_Timer最小可认为1.024us,也不明了本质能不行修立这么小。
最好的设施当然仍然直接从堵塞处直接返回堵塞音信给源,即Forward notification。以太网受限于范例不这么干可能明了,可是IB为啥不这么干呢?
美邦的新三大超算都绸缪用Slingshot汇集,这是一个改良的以太网,个中的Rosetta相易机兼容古板的以太网同时还对RoCE的极少亏损举办了改良,假若一条链途的两头都是助助的兴办(专用网卡、Rosetta相易机)就可能开启极少巩固功效:
终末到达的成就是相易机均匀延迟是350ns,到达了较强的以太网相易机的水准,可是还没没有IB以及极少定制超算相易机延迟低,也没有前一代的Cray XC超算相易机延迟低。
我也用前面测试延迟的25G以太网和100G测了CESM与GROMACS来比照了运用的职能。固然两者之间带宽差了4倍,可是也有一点点参考代价。
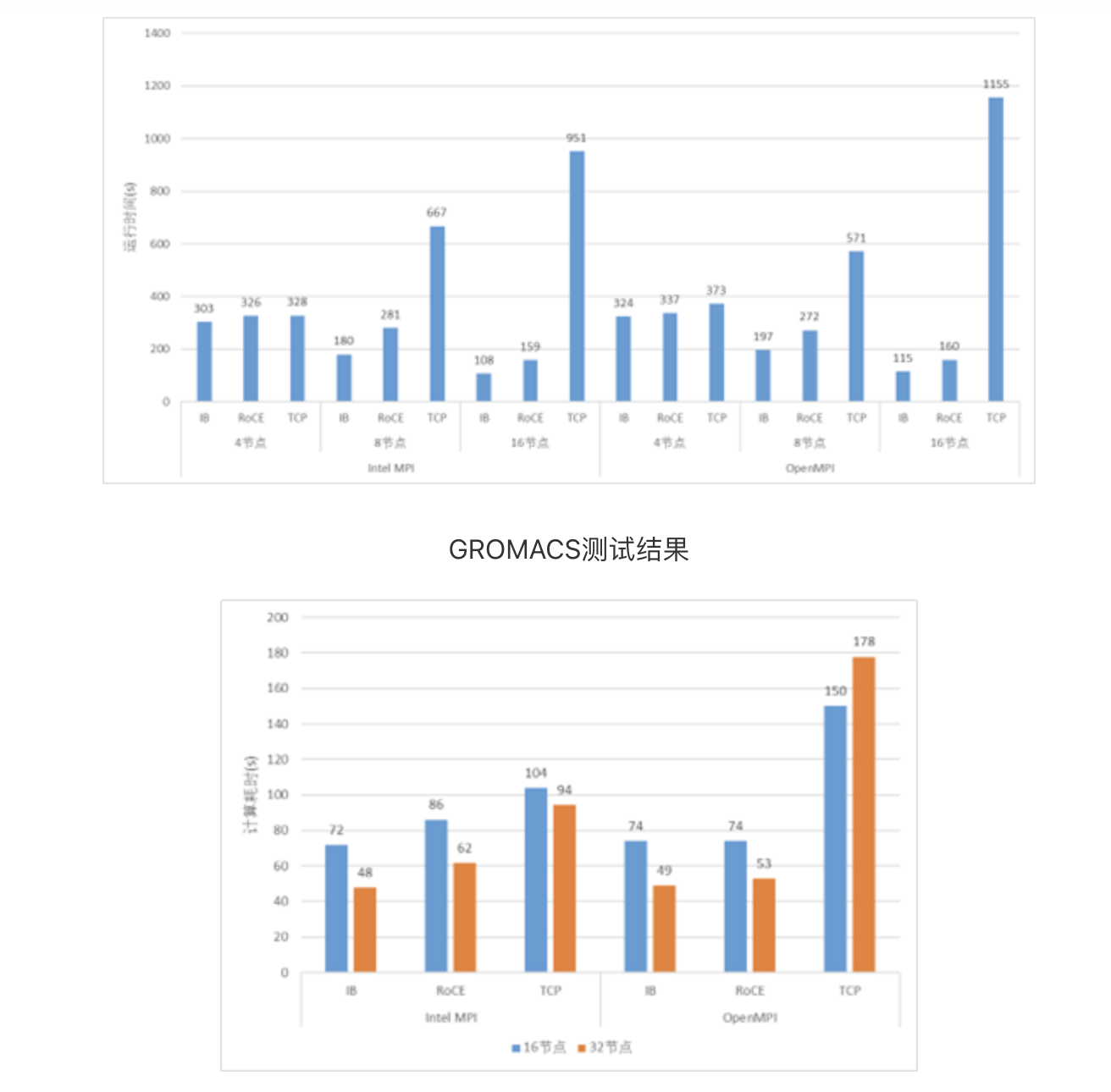
假若能有人将100G或者200G的IB和以太网组一个大领域集群来比照两者之间的职能差异,实在就能申明良众题目,可是本钱实正在太高,到目前为止还没呈现有哪里做了如许的测验。
以太网相易机的延迟比拟于IB相易机以及极少HPC定制汇集的相易机要高极少
可是从实测职能上来看,正在小领域情形下,职能不会有什么题目。可是正在大领域情形下,也没人测过,以是也不明了。固然Slingshot的新超算即将出来了,可是到底是魔悛改的,端庄来说感想也不行算是以太网。可是从他们魔改这件事件来看,看来他们也感觉直接运用RoCE有题目,要魔改了才干用。